GRU e LSTM
obs: Não vou me demorar tratando de questões teóricas sobre as RNN em si, já que o foco dessas anotações é NLP, futuramente, ao concluir essas anotações talvez eu inicie uma série mais abrangente sobre machine learning, mas por enquanto apenas traterei de assuntos teóricos relativos a NLP e ao resto apenas uma abordagem prática.
Parece meio óbvio dizer mas o que define uma rede neural recorrente é exatamente a recorrência, isto é, informações que são armazenadas e depois reutilizadas, a forma mais simples de implementação consiste em criar uma camada (um array) que armazena os resultados e é utilizado normalmente no processamento dos dados que passam por uma rede neural, só que com 1 caracérística distinta: haver uma condição ou não para atualizar esses dados aprendidos ao longo do treinamento e uma condição que a informação armazenada seja utilizada.
Devido a esse mecanismo ser claramente um gerenciamento de memória e estarmos tratando de redes neurais, não demora muito para começarmos a associar ao modo como nosso cérebro gerencia a memória, desta forma vem ao mundo em 1997 o LSTM (Long Short-Term Memory) [1] [2], e como o nome bem indica, se trata de gerenciamento de memória de curto e longo prazo, posteriormente, em 2014 nasce o GRU (Gated Recurrent Unit) [3], mantendo diversas semelhanças com o LSTM porém com um custo computacional um pouco menor mas que no geral tem um desempenho semelhante ainda que é comum encontrar artigos falando que um ou outro método funcionou bem melhor em algum caso específico. Mas aqui estamos tratando de entender por alto como funciona esse gerenciamento de memória, o que precisamos ter noção é de como eles fazem isso?
Portões
Portões == funções
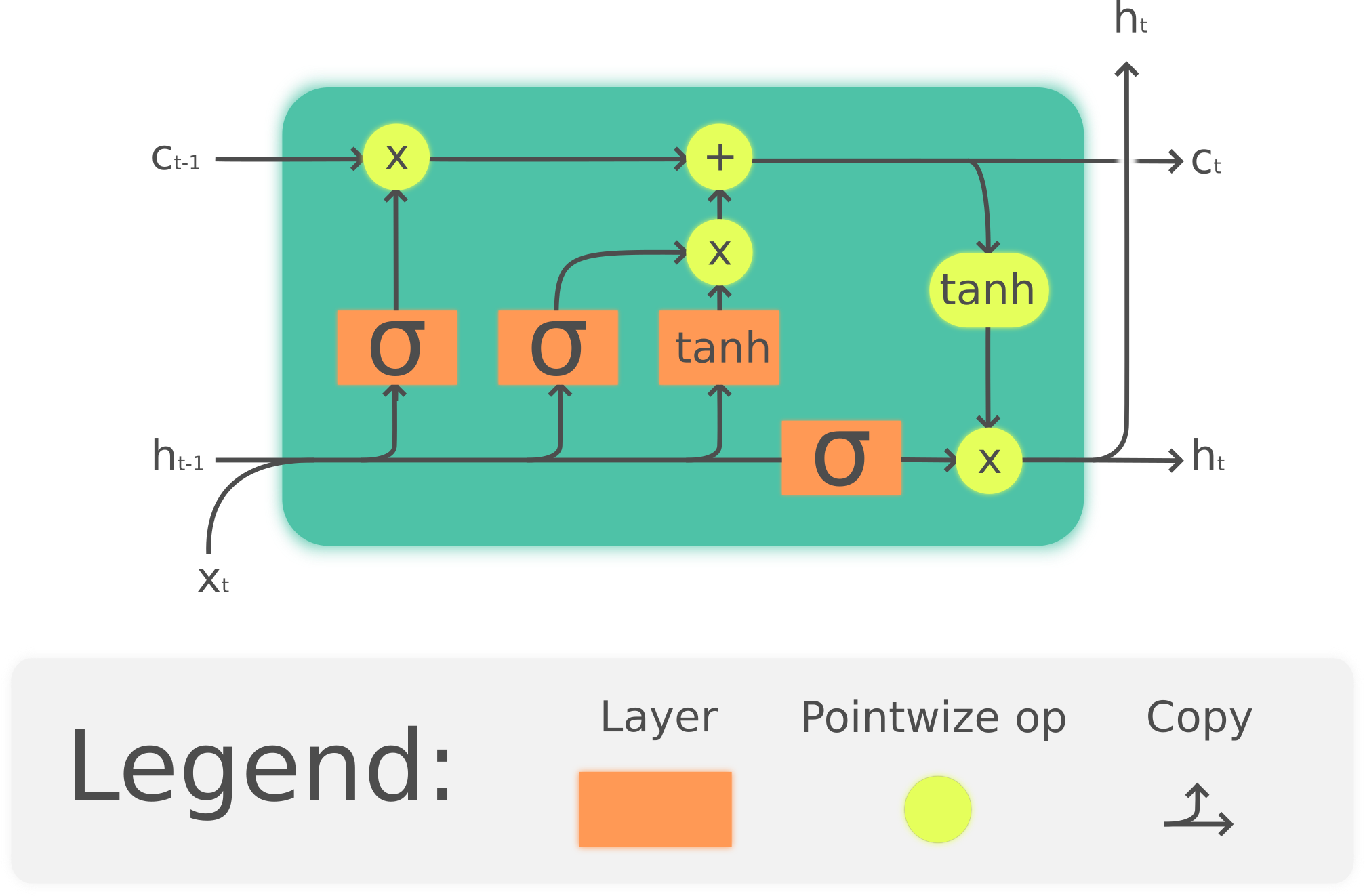
Explicando as imagens acima: a primeira mostra como funciona o LSTM e a segunda mostra como funciona o GRU, ainda que os diagramas sejam diferentes, vemos que as funções usadas, os "portões" são os mesmos embora aplicados de diferentes formas, como são as funções que importam para entender aidéia geral, vou direto à explicação sobre as funções.

Vemos que a diferença entre os gráficos dessas funções é essencialmente o limite quando tende a menos infinito, e isso faz toda a diferença, pois um limite que tende a 0 significa que posteriormente qualquer número multiplicado por 0 será 0, neste caso a função sigmoide indica a relevância de cada dimensão de entrada, se a dimensão for próxima a zero, ela vai perdendo relevância até desaparecer ou ser substituída por outra informação mais relevante (decidida pela função tanh).
Todo o mecanismo de preservação e esquecimento desses métodos se baseia nesses "portões" que é como são chamadas as camadas com a função sigmoide, enquanto a função tanh tem o dever de fazer as escolhas finais, repare nas somas e multiplicações que unem o fluxo da saída com a camada oculta que armazena a memória, como a última estapa das operações com o estado da célula é sempre uma soma e os anteriores são multiplicações, isso revela a alteração dos pesos para definir a importância de cada dimensão e posteriormente a atualização mantendo assim para a época atual do treinamento da rede neural, a memória de curto prazo (os espaços próximos a zero que após a soma se mantém próximos aos resultados mais recentes) e a memória de longo prazo (o conteúdo mais relevante deixado mais próximo de 1)
---
artigos e links recomendados
Uma das melhores explicações que já encontrei sobre LSTM e GRU: Illustrated Guide to LSTM’s and GRU’s: A step by step explanation
| [1] | Learning to Forget: Continual Prediction with LSTM ( Felix A. Gers , Jürgen Schmidhuber , Fred Cummins ) |
| [2] | Long short-term memory (Sepp Hochreiter; Jürgen Schmidhuber) |
Comentários
Comments powered by Disqus